RealMysql 1권에서 트랜잭션부분에서 읽고 쓴 글입니다.
이 책을 추천받고 매우 흥미롭게 지식을 쌓을수 있었는데 여러분들도 꼭 읽어보시길 추천드립니다.
먼저 트랜잭션이란?
작업의 완전성을 보장해주는 것을 뜻한다고 하는데
하나의 트랜잭션으로 묶인 모든것들이 완벽하게 일을 끝내는것, 혹은 실패시에 모든것을 되돌려 놓는것 (roll back)
을 뜻합니다. 여기서 RDBMS의 ACID중 원자성에 일을 맡게 하는 친구입니다.
여기서 Lock의 기능과 주의하셔야 하는데 트랜잭션이란 작업의 단위를 하나로 묶어서 데이터의 정합성을 보장, 즉 끝냈을때 일을 완벽히 처리하는것을 목적으로 하며, Lock은 데이터의 동시성을 제어하기 위한 기능입니다.
우리의 어플리케이션은 여러 트랜잭션이 동시에 발생하고 있기 때문에 트랜잭션끼리의 작동이 어떻게 되는지 알고 사용하셔야
정확하게 트랜잭션을 사용할 수 있습니다. 따라서 여러 DBMS에서는 트랜잭션의 격리수준을 정해놓았고
저는 책에 나온 Mysql 8.0 이상을 기준으로 하겠고 기본으로 쓰이는 InnoDB기준으로 하겠습니다.
InnoDB 스토리지 엔진은 책을 두번더 읽은뒤 완벽하게 이해한뒤에 자세하게 작성해보도록 하겠습니다.
트랜잭션 사용시 주의점
이 책에서 강조하는 내용과 여러 개발자님들이 강조하시는 내용중 하나는
꼭 필요한 최소의 코드에만 트랜잭션을 적용하는 것이 좋다고 합니다.
이는 데이터베이스에 연결하기 위해서 어플리케이션에서 트랜잭션을 지연되게 사용하거나, 불필요한 트랜잭션으로 인해
예기치 못한 상황등이 발생 할 수 있는데, 아래 예시를 들어보겠습니다.
가정 상황
- 데이터베이스 커넥션 생성
- 트랜잭션 시작
- 사용자 로그인
- 사용자 글쓰기 내용 오류 여부 확인
- 같이 업로드된 파일 확인 및 저장
- 사용자 입력 정보 DBMS에 저장
- 첨부 파일 정보를 DBMS에 저장
- 게시된 내용 혹은 정보를 DBMS에서 조회
- 게시물 등록에 대한 알림 메일 발송
- 알림 메일 발송 이력을 DBMS에 저장
- 트랜잭션 종료
- 데이터 베이스 커넥션 반납
- 완료
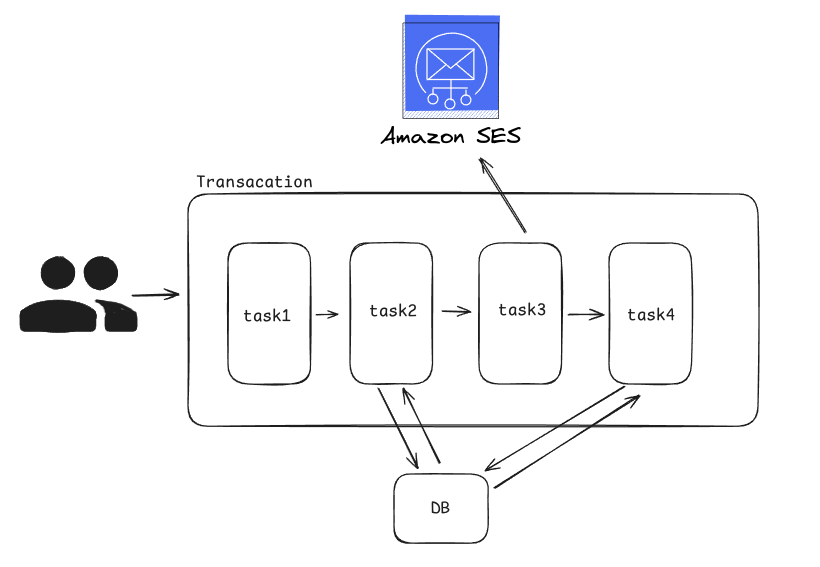
전체 과정이 하나의 트랜잭션으로 묶여있습니다. 그림으로 가정하면 다음과 같은 상황입니다.
하지만 실제로 DBMS에 적용하는 부분은 6번부터 시작되어 10번에서 끝나게 됩니다.
6-10 을 하나의 트랜잭션으로 묶는 방법은 서비스로직에 따라 다르겠지만 하나의 트랜잭션으로 묶어도 이상해보이지 않습니다.
그러나 이렇게 된 경우 긴 트랜잭션으로 인해 사용자가 많아질 경우 데이터베이스의 커넥션 개 수가 빠르게 소진될 위험이 있습니다.
추가로 또다른 위험성이 존재합니다.
바로 9번에서 외부 네트워크와의 트랜잭션이 함께 적용되어있습니다. 이렇게 외부와의 통신이 길어지거나이러한 네트워크를 통해 외부 서버와 통신하는 부분은
트랜잭션에서 제거하는 편이 좋은데 만약에 9번이 실패하거나 메일 발송 서버에서 너무 늦게 응답을 주게 되면 어떤일이 발생할지
생각이 드실겁니다.
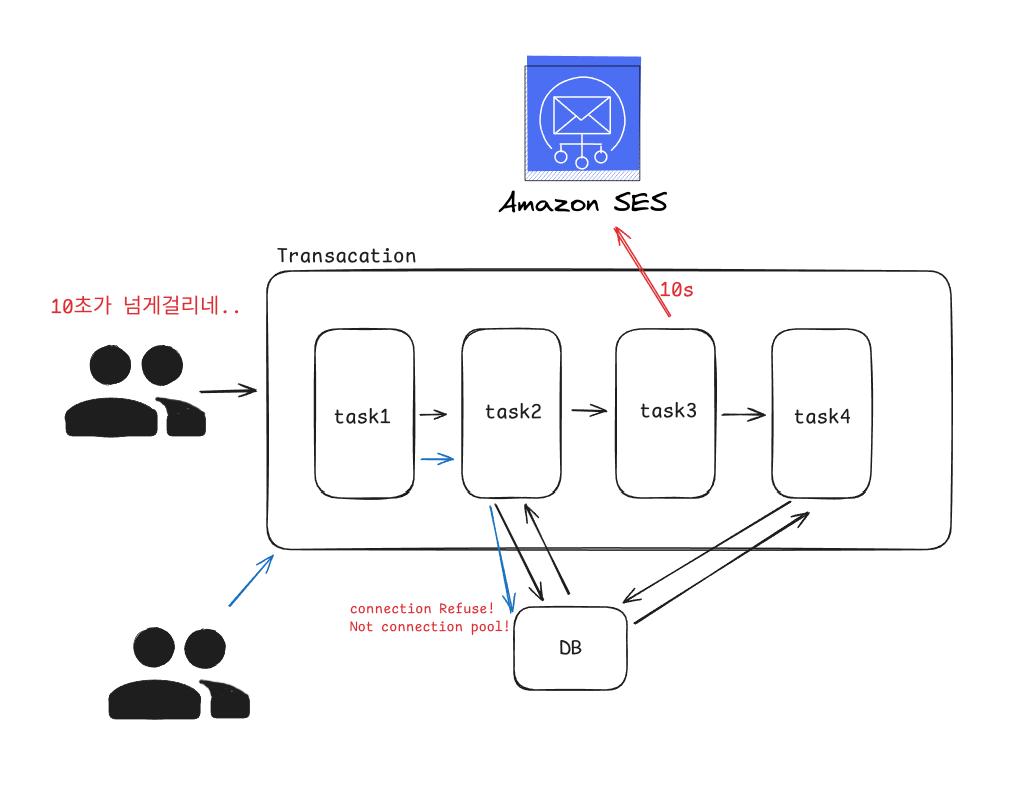
바로 네트워크에 대한 응답을 받을때까지 계속해서 커넥션을 붙잡고 있게 되고 트랜잭션은 계속해서 네트워크의 응답을 받을때까지 기다리게 됩니다. 따라서 트랜잭션을 적절히 분리한다면 다음과 같이 가정할수 있을 것 같습니다.
- 사용자 로그인
- 사용자 글쓰기 내용 오류 여부 확인
- 같이 업로드된 파일 확인 및 저장
- 데이터 베이스 커넥션 생성이후 트랜잭션 시작
- 사용자 입력 정보 DBMS에 저장
- 첨부 파일 정보를 DBMS에 저장
- 트랜잭션 종료
- 게시된 내용 혹은 정보를 DBMS에서 조회
- 게시물 등록에 대한 알림 메일 발송
- 트랜잭션 시작
- 알림 메일 발송 이력을 DBMS에 저장
- 트랜잭션 종료
- 데이터 베이스 커넥션 반납
- 완료
같은 일을 하지만 내부적으로 트랜잭션이 적용되는 범위가 다릅니다.
따라서 이런 방식으로 데이터베이스 커넥션에 대한 범위를 최소화 하는 방식으로 프로그래밍을 해야 함을 책에서는 매우 강조하고 있습니다.
MySQL의 격리수준
트랜잭션의 격리 레벨을 아는 것은 또한 매우 중요합니다.
여러 트랜잭션의 로직이 복잡하게 얽혀있고 이를 처리하기 위해서 꼭 트랜잭션 레벨을 알아야 합니다.
트랜잭션에는 다음과 같은 4가지레벨이 있는데 각 격리수준이 어떻게 동작하는지와 왜 이렇게 나누었는지 아는것이 중요하다고 생각한다. 이러한 격리수준에 따라 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 값을 조회할수 있는지에 허용여부가 다르다.
- READ UNCOMMITED
- READ COMMITED
- REPETABLE READ
- SERIALIZABLE
DIRTY READ라고 불리는 READ UNCOMMITED는 일반적인 데이터베이스에서 거의 사용하지 않고
SERIALIZABLE 또한 동시성이 중요한 데이터베이스에서는 거의 사용되지 않는다.
이렇게 트랜잭션간의 격리수준이 높아짐에 따라, 동시성 처리능력 또한 감소되는데 사실 SERIALIZABLE 격리수준이 아니라면 크게 성능저하가 발생하지 않는다고 한다.
현대 DB에서는 온라인에서 주로 READ COMMITED나 REPETABLE READ중 한가지를 선택하며
오라클에서는 주로 READ COMMITED, REPETABLE READ는 Mysql에서 주로 사용한다.
READ UNCOMMITED
말그대로 읽다 + 커밋되지 않은 것 을 해석해보면 쉽다.
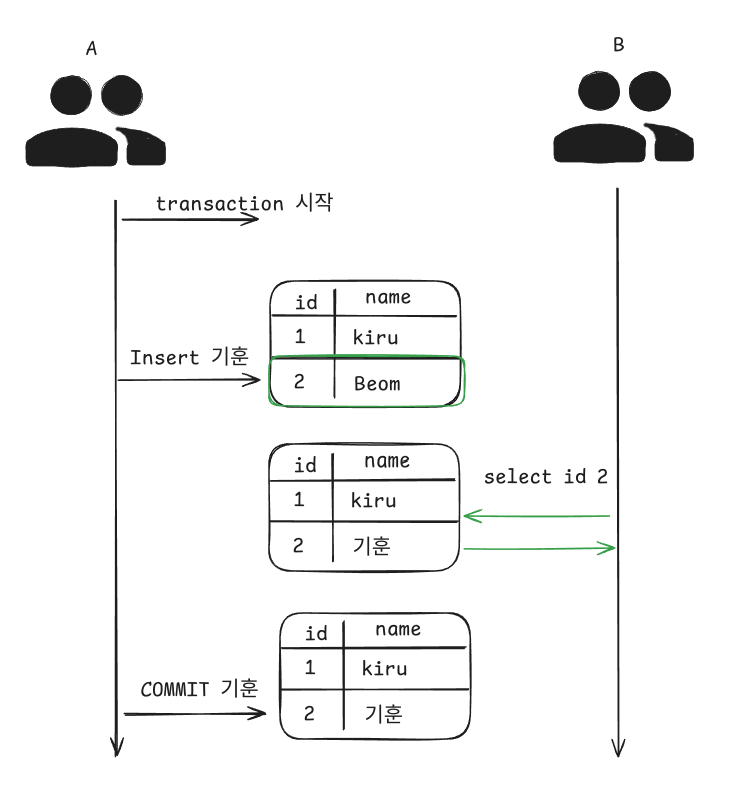
다음 상황은 커밋이 되지 않은 상황에서도 트랜잭션 내부에서 변경내용이 커밋이나 롤백 여부에 상관없이 다른 트랜잭션에게 보이게 된다. 위에서 문제 상황은 A가 알수없는 문제로 인해 INSERT 된 내용을 롤백한다고 하더라도
사용자 B는 이미 select 를 통해서 데이터를 가져가 처리할수 있다는 상황이다.
이처럼 트랜잭션에서 처리한 작업이 완료되지 않았는데도 다른 트랜잭션에서 볼수 있는 상황을 DIRTY READ라고 하며
READ UNCOMMITED에서 일어난다. 또한 이는 RDBMS 표준에서 인정하지 않을 정도로 정합성에 문제가 많다고 하며
최소한의 격리레벨을 이것으로 설정하지는 말자.
READ COMMITED
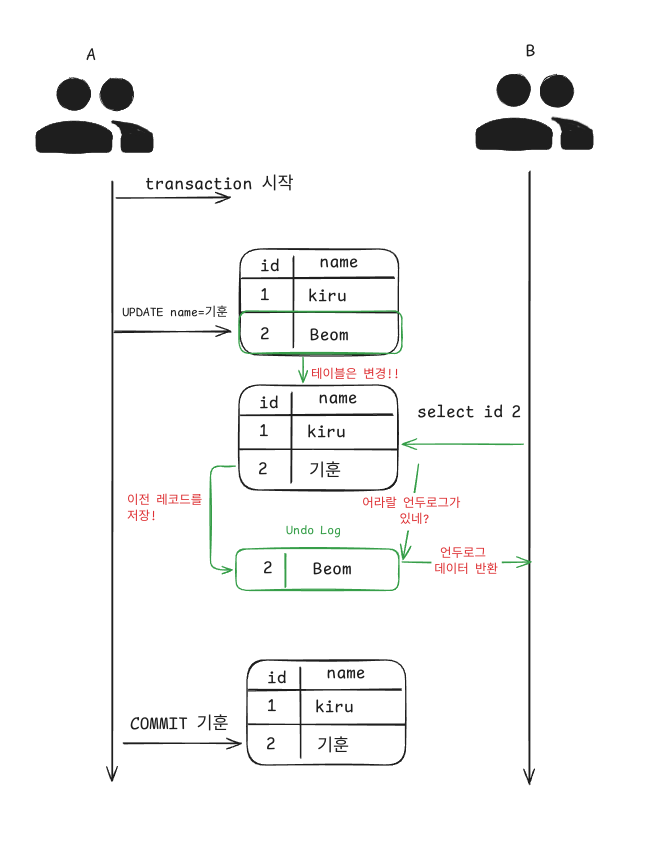
다음 그림으로 보면 이해가 쉬울것이다. READ COMMITED는 오라클 DBMS에서 기본격리수준이며
온라인에서 가장 많이 선택되는 격리수준이다.
이때는 DIRTY READ는 발생하지 않고 어떤 트랜잭션에서 데이터를 변경했다 하더라도 Commit이 완료되기 전까지
변경한 데이터를 읽지 않는다. 이는 Mysql에서 사용하는 스토리지 엔진인 InnoDB 덕분인데 InnoDB에 대한 자세한 내용도
좀더 책을 읽고 난뒤에 자세하게 적겠다.
간단하게 말하자면 변경전의 기록을 언두로그에 백업하며, 이를 다른 트랜잭션에서 언두로그를 읽게 되면서
백업용 레코드에서 기록을 읽을수 있다.
이제 여기서 문제되는점은 NON REPETABLE READ 정합성에 문제가 생기게 되는데 이는 하나의 트랜잭션에서 똑같은 SELET 쿼리를 날린다면 쿼리 실행시에는 항상 같은 결과를 가져와야한다는 문제이다.
이 문제가 발생할수 있는 상황을 가정해보자. 위 상황에서는 A가 커밋을 하기전까지 B에서는 이전에 데이터를 읽게된다.
그러나 A가 커밋을 했을 경우 여전히 B는 하나의 트랜잭션에 참여한 상태인데 같은 SELECT 문을 날렸을때 id가 2번인 데이터가 A가 커밋한 데이터로 변경되게 된다.
일반적인 경우에서는 문제가 되지 않을수 있는 상황이지만 동일한 데이터를 읽고 변경하는 작업이 금융권이나 금전적인 문제와 연관된다면 문제가 될수 있다.
한 트랜잭션에서 입금,출금을 반복적으로 수행하고 다른 트랜잭션 (B)에서는 입금된 금액의 총합을 계산한다고 가정하자.
이때 REPETABLE READ가 보장되지 않기 때문에 총합을 계산하는 SELECT 쿼리가 실행될때마다 다른 결과를 가져온다.
(물론 이것이 같은 트랜잭션에서 수행된다고 가정한 것이다)
여기서 중요한 것은 사용중인 격리수준에 따라 SQL문이 어떤 결과를 가져오는지 정확하게 예측가능해야 한다는 점이며, 이를 위해서는 격리수준이 어떻게 동작하는지 알아야한다.
많은 오해가 있는데 트랜잭션 내에서 실행되는 SELECT와 트랜잭션 없이 실행되는 SELECT문장에 차이를 혼동하는 것이다.
READ COMMITED 격리수준은 트랜잭션 내에서 실행되는 Select와 트랜잭션 외부에서 실행되는 SELECT 구문은
차이가 "별로" 없다.
하지만 REPETABLE READ 격리 수준에서는 기본적으로 SELECT 쿼리 문장도 트랜잭션 범위 내에서만 작동한다.
즉 트랜잭션 내에서 하루종일 SELECT를 해도 같은 결과를 반환한다는 것이다. 이런 문제로 데이터의 정합성이 깨지고 어플리케이션 버그가 발생하면 찾아내기 쉽지 않다고 하니 미리 아는 것이 중요하다.
REPETABLE READ
mysql 의 InnoDB 스토리지 엔진의 기본 격리 수준이다.
이 수준에서는 READ COMMITED에서 발생하는 NON REPETABLE READ 부정합이 발생하지 않으며
innoDB 엔진은 트랜잭션이 롤백될 가능성에 대비해 변경전 로그를 언두로그에 기록하고 실제 로그를 테이블에 기록한다.
이러한 변경 방식덕분에 MVCC (Multi Version Concurrency Control)을 적용할수 있다.
REPETALBE READ는 MVCC를 통해서 언두 영역의 백업된 이전 데이터를 통해서 동일한 트랜잭션에 참여하고 있는 사용자들에게 동일한 결과를 보여줄수 있도록 보장한다.
READ COMMITED과의 차이는 언두 영역의 백업된 레코드의 버젼을 붙여 몇번째 이전까지 찾아보냐의 차이가 있다.
이때 InnoDB 의 트랜잭션은 고유한 트랜잭션 번호를 갖는데 언두영역에 백업된 데이터에 트랜잭션 번호와 함께 추가해 저장한다.
이렇게 백업된 데이터는 InnoDB 스토리지 엔진이 불필요하다고 생각하는 시점에 주기적으로 삭제한다.
REPETABLE READ 격리수준에서는 MVCC를 어떻게 보장하는지 알아보자.
이때 실행중인 트랜잭션 가운데 가장 오래된 트랜잭션 번호보다 앞선 트랜잭션 번호의 언두영역 데이터는 삭제하지 않는데
그림을 함께 보면 이해가 쉬울 것이다.
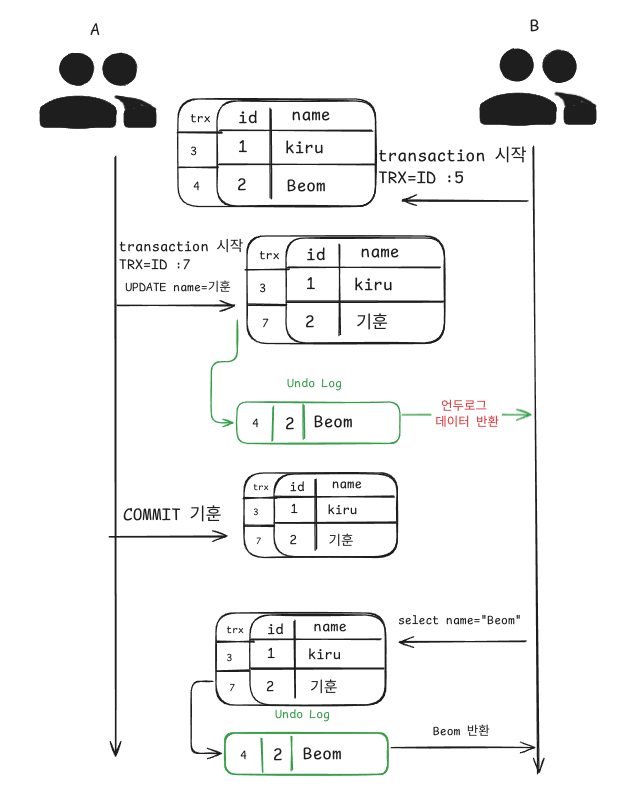
다음과 같은 상황에서 자신의 트랜잭션 번호보다 낮은 트랜잭션 번호의 언두로그를 읽게 되면서 A에서 몇번을 Update하고 Commit하든 같은 트랜잭션이라면 몇번이든 같은 데이터를 보게 된다.
이때 주의점은 언두영역의 백업된 데이터가 얼마든지 존재할수 있다는 점인데 B에서 트랜잭션을 종료하지 않게 되면
언두영역의 로그가 무한정으로 커질수도 있어 Mysql의 성능저하가 발생할수있으니 조심하도록 하자.
다만 여기서 문제가 되는 방식은 새로운 데이터에 대해서는 언두로그가 존재하지 않는다는점이다.
따라서 새로운 데이터의 추가나, 삭제에 관해서는 데이터가 나타났다가 지워졌다가 하는 문제가 발생하게 되는데
이러한 현상을 PHANTOMREAD 라고 한다.
select ... for update 쿼리는 select하는 레코드에 쓰기 잠금을 걸어야 하는데 언두 레코드에는 잠금을 걸수 없기 때문에
이러한 변경전 영역이 아닌 현재 레코드 값을 가져오게 된다.
SERIALIZABLE
단순하면서 엄격한 기준이며 동시성 성능도 떨어진다.
innoDB에서 select 작업은 어떤 레코드 잠금도 없이 실행되는데
innoDB에서 non locking consistent read라는 말이 이를 의미한다.
하지만 트랜잭션 격리수준이 serializable로 설정되면 읽기 작업도 읽기 락을 획득하며
다른 트랜잭션에서 레코드 변경이 불가능하다. 즉 읽기 과정에서 다른 트랜잭션이 접근 불가능하며
이때는 팬텀 리드도 발생하지 않지만 innoDB 스토리지 엔진에서는 갭락과 넥스트락을 적용해서 이미 REPETABLE READ 격리수준에서도 팬텀 리드가 발생하지 않기 때문에 굳이 Serializable을 사용할 필요성은 없다고 한다.
'DB' 카테고리의 다른 글
| [DB] JAVA 개발자라면 알아야 하는 SQL Best Practice (3) | 2024.10.23 |
|---|---|
| [DB] Redis Cluster Docker Compose로 구축하기 (4) | 2024.10.22 |
| [DB] Redis Cluster (5) | 2024.10.19 |