먼저 이 글은 "실전 레디스"라는 책을 읽고 나서 적은 글이다.
24년 5월에 발행한 따끈따끈한 책이기도 했고 시중에 생각보다 redis에 대한 내용으로 책이 없었는데 마침 redis에 빠져서 공부를 하다 보니 생각보다 좋은 내용들이 많으니 읽어보시는 것을 추천드린다.
Redis Cluster란?
레디스 클러스터는 여러 캐시노드를 연결하여 일부 장애가 발생해도 시스템을 계속 운영할수 있도록 자동 Failover 기능을 지원한다.
또한 샤딩을 통해 레디스 서버가 실행중일때 노드 사이의 키를 옮길 수 있다. 레디스 클러스터는 failover와 sharding을 통해 높은 가용성을 보장하며, 읽기 쓰기 작업의 확장성을 높일 수 있다.
모두 여기서 들어왔을때는 CPA 이론에 대해서 어느 정도 알고 있다고 가정하겠다. 간단히 소개하자면 분산 환경에서
CAP 이론은 어떠한 분산 데이터 베이스 시스템도 일관성 (Consistency), 가용성 (Availability), 네트워크 파티션 허용 (Partition tolerance) 중에 3가지를 동시에 만족시킬 수는 없다는 이론이다.
분산환경에서 네트워크 오류같은 문제는 여전히 해결할 수 없는 문제이므로 P는 거의 필수로 들어가 대부분 C와 A사이의 트레이드오프를 고려하여 설계를 해야 한다.
Redis Centinel이랑 어떤 차이점이 있는가?

위 센티널의 구조를 보면 센티널은 One master - N slave 구조로 이루어져 있다. 센티널의 목적은 인스턴스의 장애 모니터링, 알림을 제공하여 고가용성을 확보하는 것에 목적이 있다. 하지만 이런 경우에도 문제가 될 수 있는 점은 여전히 master는 1개이며 모든 연결이 하나의 마스터로 향한다는 것이다. 여전히 master에 과부하가 생기는 것이며, 이는 마스터에게 좋지 못한 경험이 될 수 있다.
그렇다면 레디스 클러스터는 어느것에 장점이 있는 것일까?
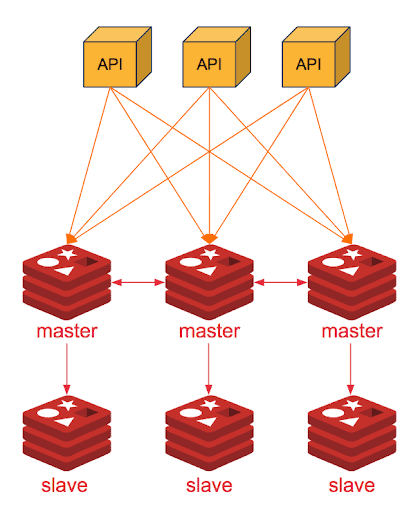
위 사진을 보면 각 연결이 분배되어 처리한다. 이렇게 데이터 샤딩을 진행해서 연결을 분배하고 상태는 N master - M slave 구조가 된다. sentienl 모드와 유사하게 고가용성을 제공하지만 샤딩을 통해서 클러스터에 더 많은 데이터를 저장할 수 있으며,
scale up에 대해서 하나의 master를 여러 복제본으로 나누어가진 센티널과 달리, 클러스터는 각각의 master-slave를 하나의 샤드로 나누어 scale-out 구조가 가능하게 만들었다.
다만 목적성에 좀더좀 더 생각할 필요가 있는데 센티널은 고가용성 문제로 인해 소규모 구현에 좀 더 적합하다. 여전히 싱글스레드로 사용할 수 있기 때문에 소규모의 프로젝트에서 좀 더 사용하기 편리하며 트랜잭션 지원까지 된다.
그러나 클러스터는 대규모 구현에 대한 방식을 목적으로 만들어졌는데, 데이터를 분할하고, 자동 Failover에 초점을 맞췄다. 따라서 자신의 프로젝트의 형태에 맞는 구조를 사용하기를 바란다.
하지만 둘다 시스템에 고가용성을 제공하는 것은 맞다. Cloud InfraStrucutre Service의 글에서는 속도가 목적이 아니고, 고가용성이 목적이라면 센티널을 사용하고, 데이터에 액세스 할 때 빠른 속도와 고가용성을 생각한다면 클러스터를 사용하라고 권하고 있다.
이제 레디스 클러스터의 대한 장점으로 다시 돌아가서 쓰기 작업은 기본적으로 Master에서 수행되기 때문에 레플리카를 늘리는 센티널과 달리 master도 함께 늘리는 클러스터에서는 쓰기 장점이 더욱 도드라진다.
각 샤드는 한개의 마스터 + 0개 이상의 레플리카로 구성되며 여러 샤드를 설정하여 샤드의 수만큼 배치할수 있다. 또한 데이터베이스 내의 데이터를 슬롯에 할당한 후 각 샤드들이 담당할 슬롯을 결정하여, 어느 샤드에 데이터를 저장할지 결정한다.
만약 레디스 클러스터에서 읽기 작업의 확장성을 높이고 싶다면 READONLY를 사용하여 레플리카에서 읽기 쿼리를 실행하도록 할 수 있다.
레디스 클러스터는 클라이언트 요청에 대해 클러스터 내 각 노드로 요청을 분배하는 과정에서 프록시를 사용하지 않아 프락시로 인한 오버헤드가 없다. 만약 데이터를 갖고 있지 않은 노드에 요청이 들어올 경우, 레디스 클러스터는 클라이언트에게 데이터를 가진 노드의 정보를 제공하고, 해당 노드로 요청을 redirect 하는 방식을 사용한다. 이 과정에서 얻은 정보를 클라이언트가 저장하고 있다면, 다음 요청부터는 리다이렉트에 대한 오버헤드도 없앨 수 있다.
그렇다면 레디스 클러스터는 어떻게 정보를 저장하는 것일까?
레디스 클러스터는 총 16384개의 해시 슬롯이 있으며, 이 슬롯은 각 샤드에 나뉘어져 할당된다. 데이터를 저장할 해시슬롯을 선택하기 위해서 키값의 해시결과를 사용한다. 이때 해시 알고리즘은 CRC16을 사용하고 이를 16384로 나눈 나머지로 사용해서 어느 slot으로 들어가게 될지 결정하게 된다.

다음과 같은 구조로 각 16384개의 master로 나누어서 할당하게 되는데 이때 예를 들어 foo 라는 키값을 CRC(16) mod 16384를 하게 되면 슬롯 12,182 값이 나온다. 즉 이 키는 shard 3번에 들어가게 되며 이때 12,182 slot에 저장되는 것이다.
레디스는 비동기 레플리케이션을 기반으로 일정수준의 가용성과 일관성을 달성할 수 있도록 설계되었다. 하지만 이 목표는 CAP에 따른 이론적 제한을 충족하기 위한 것은 아니다. 레디스는 분산 데이터베이스보다는 일관성과 가용성이 제한되지만, 실제 세계의 특성을 고려하여 기능을 구현할 수 있다고 하며 여기서 일관성 모델은 “최종 일관성”을 채택하고 있다.
레디스 클러스터가 사용하는 2개의 TCP 포트
레디스 클러스터를 연결하기 위해서는 2개의 TCP 포트를 사용한다. 첫번재는 클라이언트로부터 TCP 연결을 받는 포트로 기본값은 6379이다. 두 번째는 클러스터 내부통신을 위한 포트로, 기본값에 10000을 더한 포트를 사용한다. 이를 cluster bus port라고 한다
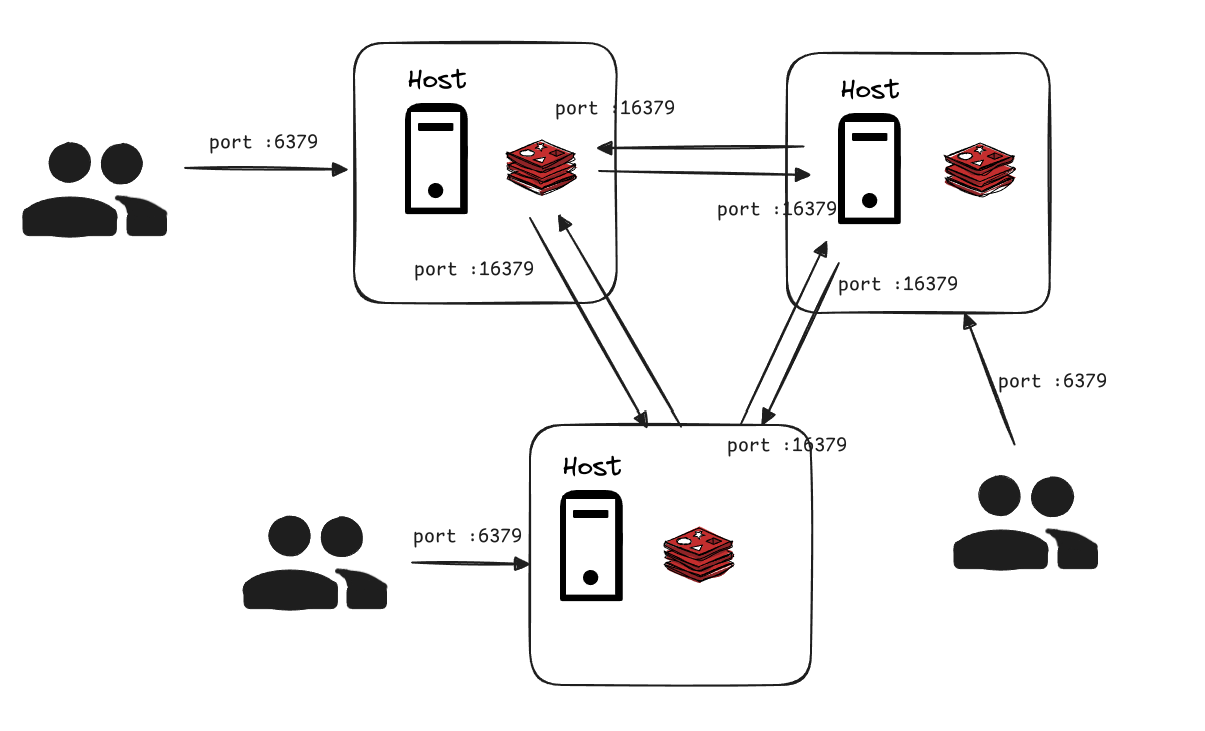
위 그림에서는 모두 6379 , 16379 포트를 사용하는데 NAT나 포트 포워딩을 사용하는 도커와 같은 컨테이너 환경에서는 Master에서 보이는 Replication의 IP 주소나 포트번호가 달라질 수 있다. 따라서 클러스터 내 다른 캐시노드의 자신의 캐시노드 IP와 클러스터 버스포트를 임의의 값으로 설정할 수 있다. 레디스 클러스터 내에서 노드 간의 통신할 때는 Cluster bus port를 사용한다. 이 포트를 사용하는 통신 채널을 클러스터 버스라고 부르며 각 노드는 클러스터 버스를 통해 다른 모든 노드들과 연결된다.
통신에는 이진 프로토콜이 사용된다. 노드는 Full Mesh 구조로 구성되며, 노드 간에는 구성정보, 상태와 같은 정보들을 교환한다.
풀메시 구조란 다음과 같이 모두 연결되어 있다는 뜻이다.

또한 페일오버 인증, 설정 업데이트에 사용되는 하트비트 패킷 교환도 이루어진다. 이와 같은 통신 방식은 가십 프로토콜을 통해 이루어지는데 이 프로토콜은 클러스터의 노드 수가 증가해도 노드 간 메세지수가 지수적으로 증가하지 않도록 고안되었다. 내부적으로는 클러스터 내의 노드간 설정 정보를 서로 공유하고 인지하기 위해 Raft라는 분산합의 알고리즘을 기반으로 시스템이 구현되어 있다. 하트비트 패킷교환이나 가십 프로토콜 같은 경우에는 관련 정보가 많고 "가상면접으로 보는 대규모 시스템 설계" 책을 읽어보면
그중에 안정적 해시설계 부분이 있는데 그 부분을 읽어보면 이해가 쉬울 것이다.
동작 메커니즘
레디스 클러스터에서 클라이언트의 요청을 처리하는 과정의 흐름을 알아보자. 레디스 클러스터에서 클라이언트 요청 처리는 다음과 같은 흐름을 통해 진행된다.
- 클라이언트가 클러스터 ip주소 중 하나에 접속
- 해당 노드가 레플리카 마스터인 경우에 따라 분기한다.
- 레플리카인 경우
- 읽기 쿼리 : 클라이언트 설정에 따라 READONLY 명령어 실행 여부에 따라 동작한다.
- READONLY 가 설정되어 있고, 해당 키가 슬롯 범위 내에 있는 경우
- 요청된 캐시 노드에서 요청을 처리한다.
- 그 외에 경우 :
- 레디스 서버가 MOVED 리다이렉트를 클라이언트에 응답한다.
- 클라이언트가 MOVED 리다이렉트를 받고 로컬 슬롯 매핑을 업데이트함
- 클라이언트가 해당 키의 슬롯을 가진 샤드의 마스터에 접근
- READONLY 가 설정되어 있고, 해당 키가 슬롯 범위 내에 있는 경우
- 쓰기 쿼리
- 레디스 서버가 MOVED 리다이렉트를 클라리언트에게 응답
- 클라이언트가 MOVED 리다이렉트 받고 로컬슬롯매핑을 업데이트
- 해당키를 가진 슬롯의 샤드의 마스터에 접근
- 읽기 쿼리 : 클라이언트 설정에 따라 READONLY 명령어 실행 여부에 따라 동작한다.
- 마스터인 경우
- 해당 키가 슬롯의 범위 내인경우
- 요청된 마스터에서 처리
- 슬롯범위 밖인 경우
- 레디스 서버가 MOVED 리다이렉트를 클라이언트에 응답
- 클라이언트가 MOVED 리다이렉트를 받고 로컬 슬롯매핑을 업데이트
- 클라이언트가 해당 키의 슬롯을 가진 샤드의 마스터에 접근
- 해당 키가 슬롯의 범위 내인경우
- 레플리카인 경우

이때 3 같은 경우에는 클라이언트에서 레디스 클러스터를 지원하는 경우 마스터 정보를 캐시 해두어 다음 요청에 바로 접근이 가능하게 하여 단일노드만 사용하는 수준으로 지연시간을 줄일 수 있다.
그러나 이렇게 데이터를 얻을 때에도 데이터가 한 곳에만 쌓여 접근노드에 편향이 발생할 수 있는데 다음을 확인해봐야 한다.
- READONLY 명령어를 사용하여 읽기 쿼리를 레플리카로 분산시키고 있는지 확인
마스터로만 편향된 것이 아니라면 다음과 같은 사항을 추가로 확인하자.
- DNS resolver에 의존하는 노드 IP주소 선택 방식 검토
- DNS 캐시
- 슬롯 배치 편향 및 특정 슬롯에 저장되는 아이템 크기의 편향
- 해시 태그 사용여부
레디스 클러스터 장애 탐지 (Failover)
특정 샤드의 마스터 노드나 문제가 발생하는 상황이라면?
시스템 내부에 마스터 다수가 응답하지 않는다면?
이런 경우 레디스 클러스터는 문제가 발생한 마스터가 속한 샤드 내의 레플리케이션을 마스터로 승격시키도록 동작한다.
장애 탐지 기능은 이동작의 수행 시점을 결정한다.
장애 탐지 메커니즘
레디스 클러스터의 각 캐시 노드에는 PFAIL, FAIL 두 가지로 나타낼 수 있다. 가십프로토콜을 사용하여 주기적으로 핑을 보내게 되는데 이때 포함된 내용에는 다른 노드의 상태정보를 담고 있는 가십 부분이 있다. 클러스터 내의 노드들은 신뢰할 수 있는 노드에서 다른 노드의 상태를 정보를 공유하는 형태로 노드 간의 상태를 파악한다.
PFAIL은
- Possible Failuer의 약어이다.
- 특정 노드가 다른 노드에 핑을 보내고 cluster-node-timeout이내에 응답이 오지 않을 때
- 해당 노드는 로컬 정보에서 핑대상 노드를 PFAIL로 표시한다.
- cluster-node-timeout /2 만큼의 시간이 지나도 핑 응답이 오지 않으면 연결을 다시 시도함
- 마스터 노드가 PFAIL 상태일 때는 failover를 수행할 수 없다.
FAIL은
- FAIL 상태가 되어야 마스터의 Failover를 수행할수 있다.
- PFAIL에서 다음 조건에 따라 FAIL로 변한다.
- 과반수의 마스터 노드가 대상 노드를 PFAIL 혹은 FAIL 상태로 판단하는 경우, 해당노드는 FAIL 상태가 된다.
- 판단에 걸리는 시간은 cluster-node-timeout * cluster-replica-validity-factor로 계산한다.
cluster-replica-validity-factor의 지시값이 0으로 설정되어 있으면 , 마스터-레플리카의 연결에 끊어진 시간에 관계없이 페일오버가 실행된다. 레디스 클러스터의 페일오버는 마스터 노드의 과반수가 정상작동하고 있는 것을 전제로 하기 때문에 일부 노드가 사용 불가능하더라도 복구된다. 하지만 클러스터 내 대부분의 노드가 사용불가능한 상태라면 복구되지 않는다. 오픈소스 버전의 클러스터는 소규모의 부분적인 장애복구를 목표로 하기 때문에 범위가 넓은 장애인 경우에는 적합하지 않다.
이런 동작 방식 때문에 클러스터는 네트워크 장애로 연결이 끊어지면 데이터가 손실될 위험이 있다. 예로 한 샤드가 마스터, 레플리카로 구성되어 있고 장애가 발생한 동안 샤드 내에서 마스터가 두 개로 나뉜 상황이라고 하자.
장애 복구 과정에서 각 마스터에 저장된 데이터를 병합할 때는 last failover wins 방식을 사용하여 마스터를 포함하는 레플리카가 새로운 마스터로 승격되며 승격되지 않은 다른 마스터의 기록은 손실된다. 또한 샤드 내에 마스터와 레플리카간의 레플리케이션은 비동기적으로 이루어진다. 따라서 마스터에 데이터를 저장한 후 클라이언트에 응답을 반환하여 레플리카에 데이터가 기록되는 일련의 과정 중에 마스터에 장애가 발생하면 레플리카에 기록되지 않은 데이터는 손실될 수 있다.
레플리카 선출
마스터가 동작하지 않으면 레플리카는 자동적으로 새로운 마스터로 페일오버를 실행한다.
다음 조건을 만족하는 레플리카가 마스터 후보가 되며 선출 프로세스가 시작된다.
- 레플리카 마스터가 FAIL 상태
- 마스터가 하나 이상인 슬롯을 관리한다.
- 레플리카가 일정 시간 마스터와 연결이 끊긴 상태여야 한다.
레디스 클러스터에서 레플리카를 새로운 마스터로 선출하는 과정은 다음과 같다.
- 마스터가 FAIL 상태를 감지한 레플리카는 일정 시간 대기한 후 클러스터 각 마스터에게 FAILOVER_AUTH_REQUEST 패킷을 브로드 캐스팅한다.
- 이때 cluster-node-timeout *2 시간만큼 대기한다.
- 각 마스터는 해당 패킷을 받으면 FAILOVER_AUTH_ACK으로 응답한다 (투표) 마스터는 각 에폭마다 한 번만 투표할 수 있으며, 마스터가 가진 lastVoteEpoch 보다 오래된 currentEpoch의 투표는 반영하지 않는다.
이후 cluster-node-timeouot *2 시간 동안 다른 레플리카로부터의 패킷에는 응답하지 않는다. - 레플리카는 currentEpoch 이하의 에포크 응답을 무시하고 그렇지 않은 경우는 반영한다. 과반수에 도달하지 못하면 cluster-node-timeout *2 시간 동안 대기한 후 cluster-node-timeout *4의 시간 후에 재투표를 진행한다.
과반수 마스터로부터 투표를 받으면 해당 레플리카가 승격대상으로 페일오버가 발생한다. - 새로운 마스터가 된 노드는 다른 마스터보다 크게 configEpoch를 증가시킨다.
다음으로 레플리카 관점에서 DELAY 시간은 마스터가 fail 상태임을 감지한 후 500 ms 동안 기다린 후 각 마스터에게 투표요청을 보낸다. 이 500 고정시간은 클러스터 내에서 마스터가 FAIL 상태임을 전파하기 위한 시간이다. DELAY의 무작위 지연은 레플리카가 동시에 선출되는 것을 막기 위해 일부러 넣은 값이다. REPLICA_RANK는 레플리카 그룹 내에서 레플리케이션 진행상황이 빠른 순서대로 번호를 매긴다. 0부터 시작해 차례대로 부여된다.
그렇다면 이제 master관점에서 투표하는 것을 보자.
마스터의 관점에서 레플리카로 투표하기 위해 다음과 같은 내용을 따라 동작한다.
- 각 master는 lastVoteEpoch를 가지며, 인증요청의 currentEpoch가 더 작으면 투표를 반영하지 않는다. 마스터가 레플리카에 정상적으로 응답하면 lastVoteEpoch가 업데이트되고 디스크에 저장된다.
- 각 마스터는 레플리카의 마스터가 Fail 상태로 판단되는 경우만 레플리카에 투표를 진행한다.
- 인증 요청의 currentEpoch가 마스터의 currentEpoch보다 작은 경우는 반영하지 않고, 마스터의 응답은 인증 요청과 동일한 currentEpoch이다.
레디스 클러스터 키워드
이제 레디스 클러스터에서 사용하는 키워드들에 대해서 알아볼 차례다. 키워드들을 알고 어떻게 동작하는지 알게 된다면 좀 더 레디스 클러스터를 잘 활용하고 구축할 수 있게 될 것이다.
슬롯
레디스 클러스터는 각 샤드마다 하나의 마스터 , 0개 이상의 레플리카를 가지며 16384개의 슬롯이 각 샤드에 분배된다. 레디스 클러스터에 분배되는 키는 CRC16 해시함수를 사용하여 해시값을 계산하며 그 값을 16384로 나눈 나머지를 구하고 해당값의 슬롯을 가진 샤드는 요청을 처리하게 된다.
즉 함수로 표현하면 다음과 같다.
HAST_SLOT = CRC16(key) mod 16384
샤드의 데이터 분산은 키를 해싱한 결과를 슬롯에 할당하고, 각 슬롯을 다시 샤드에 할당하는 방식으로 진행된다. 이 과정은 슬롯의 개수를 기준으로 하며, 데이터의 크기는 고려하지 않는다. 따라서 특정 샤드에 데이터가 집중되는 경우, 슬롯에 편향이 생기거나 특정 슬롯에 속하는 데이터 세트의 크기가 달라질 수 있다.
슬롯의 구성은 CLUSTER SHARDS, CLUSTER NODES, CLUSTER SLOTS에서 확인할 수 있다.
해시 태그
어떤 키에 값을 저장할 때는 해당 키 이름을 해싱하여 어느 슬롯에 데이터를 저장할지 결정한 후 해당 슬롯을 가진 샤드에 데이터가 저장된다. 레디스 클러스터는 데이터의 일관성과 높은 성능을 제공하기 위해 MSET과 같이 여러키를 동시에 조작하는 명령어나 이페머럴 스크립트를 실행할 때 모든 키가 동일한 슬롯에 있어야 한다. 만약 다른 슬롯에 있는 키에 접근하려고 하면 CROSSSLOT 오류가 발생한다.
예를 들어서 key 1, key2, key3이 slot 5000, 8000, 12000에 있다고 가정하자.
그렇다면 MGET을 통해서 한번

에 key를 불러오려고 하면 에러가 발생한다.
7.0.3부터는 일관성을 보장하기 위한 방법으로 동시에 여러키를 조작할 때 키가 존재하지 않거나 혹은 리샤딩중이어서 원본 노드와 목적지 노드의 데이터가 일시적으로 분리된 경우 TRYAGAIN 오류를 반환한다.
데이터를 저장할 때는 해시태그 기능을 사용하며, 키가 달라도 같은 슬롯에 접근할 수 있게 된다.
해시태그를 사용하기 위해서 키 내의 공통 문자열을 { }로 감싸야한다.
예를 들어 user1000이라는 사용자 정보를 같은 슬롯에 저장하려면 {user1000}. following처럼 표현할 수 있다. 단 해시태그를 남용하게 되면 슬롯 간 요청에서 편향이 발생할 수 있으므로 주의한다. 또한 해시태그로 인식되려면 다음 조건을 만족해야 하며 다음 조건이 여러 개 있을 경우 가장 먼저 조건을 만족하는 것이 대상이 된다.
- 키에 { 를 포함해야 한다.
- {의 오른쪽에 }을 포함해야 한다.
- { } 사이에 하나 이상의 문자가 포함돼야 한다.
클러스터 버스
레디스 클러스터 버스는 TCP를 통해 이진 프로토콜과 풀메시 구조로 서로 연결되어 있다. 7.0부터 클러스터 버스를 cluster-port로 지정할 수 있다. 도커나 NAT 같은 포트포워딩 사용환경 컨테이너에서는 마스터 노드가 레플리카의 IP주소나 포트를 다르게 인식할 수 있기 때문에 레디스 클러스터는 클러스터 내의 다른 캐시노드들에게 자신의 캐시노드 IP와 클러스터 버스포트를 자유롭게 설정하는 기능을 제공한다.
그러면 버스를 통해 노드상태를 어떻게 파악할까 확인해 보자
노드는 가십프로토콜과 Raft라는 분산합의 알고리즘을 기반으로 각 노드의 설정정보를 공유하고 페일오버 기능을 제공한다. 각 노드는 상대 노드로 핑을 보내고 응답을 받아 해당 노드가 정상적인지 확인한다. 단 클러스터 내 모두 연결되어 있어도 모든 노드에 핑을 주고받는 풀메시를 사용하지는 않는데 그 이유는 노드수가 늘어날수록 보내는 핑의 양이 급격히 늘어나 클러스터 성능이나 네트워크 대역폭에 영향을 줄 수 있기 때문이다.
일반적으로 각 노드는 다른 노드를 무작위로 선택하여 핑을 보내고 응답을 받는다. 이 과정에서 각 노드가 보내는 전체 핑 패킷의 총량은 일정하도록 유지한다. 만약 cluster-node-timeout 설정시간의 절반을 초과하는 동안 다음 조건 중 하나라도 만족하는 노드가 있을 경우 해당하는 모든 노드에 핑을 보내도록 설정되어 있다.
- ping이 전송되지 않은 노드
- ping의 응답을 받지 못한 노드
따라서 가십프로토콜과 설정 업데이트를 통해 메시구조와 노드 개수의 확장에 따른 메시지수의 급격한 증가를 방지하고 있다.
캐시 노드가 추가되면 메세지 개수는 선형적으로 증가하지만 메세지 크기는 지수적으로 증가한다.
클러스터에 속하지 않은 노드에서 온 핑 메시지라도 수신하면 응답을 반환하지만 클러스터 외부 노드에서 온다면 패킷을 폐기한다.
노드가 클러스터 일부로 인식되는 과정은 다음과 같다.
- MEET 메세지
- CLUSTER MEET <ip> <port> 명령을 보내면 명령을 받은 노드는 대상 노드를 클러스터
- 일부로 인식한다.
- 가십 프로토콜
- 노드 A가 B에 대해 B가 알지 못하는 클러스터 내 다른 노드정보를 가지고 있을 때
- A에서 B로 보내는 가십 메시지를 통해 노드 B도 해당 정보를 인식하게 한다.
이 두 가지로 클러스터에 노드를 추가하더라도 모든 노드가 추가된 노드를 인식할 수 있다. 노드 사이의 슬롯 배치는 다음 두 종류의 메시지로 관리되며 메시지를 통해 슬롯 구성이 업데이트된다.
- 하트비트 메시지
- UPDATE 메시지
하트비트 메시지는 핑/퐁 을 보낼 때 항상 슬롯의 구성정보를 포함하여 전달한다. 이때 메시지에는 발신자의 configEpoch와 슬롯구성정보가 포함되어 있고, 수신자가 발신자의 노드정보가 오래되었다고 판단하면 UPDATE 메시지로 업데이트를 요청한다.
예로 클러스터에서 제외된 노드를 다시 추가할 때 다른 노드에 핑을 보내는 경우 정보가 오래되었다고 판단한 다른 노드는 UPDATE 메시지로 요청을 하게 되고 , 추가된 노드의 정보는 설정 변경에 관한 알림을 통해 업데이트된다.
파티셔닝
파티셔닝은 여러 레디스 인스턴스 간의 데이터 세트를 분할하여 저장하는 작업이다. 파티셔닝을 통해 여러 대의 컴퓨터 메모리의 총용량을 활용하여 더 큰 데이터베이스를 사용할 수 있고 컴퓨터 처리 능력과 네트워크 대역폭을 확장할 수 있다.
파티셔닝은 키를 분리하는 방식에 따라 레인지 파티셔닝, 해시 파티셔닝 등으로 구분할 수 있다.
레인지 파티셔닝은 간단하지만 레인지와 노드의 매핑테이블이 필요하다는 단점이 있다.
해시는 매핑테이블이 필요 없고 키의 형식에 구애받지 않는다.
파티셔닝 실행방법에는 다음 방법들이 있다.
- 클라이언트 측 파티셔닝
- 프락시 기반 파티셔닝
- 쿼리라우팅
클라이언트 측 파티셔닝은 어느 노드로 요청을 보낼지 클라이언트에서 결정하는 방식이다. 다수의 레디스 클라이언트의 클러스터 기능 사용 시 , 각 슬롯과 슬롯별 캐시노드의 매핑정보를 보관하는 방식으로 구현되어 있다.
프락시 기반 파티셔닝은 클라이언트에서 직접 노드로 요청을 보내는 대신 프락시가 클라이언트로 요청을 받아 대상 노드로 라우팅 하는 것이다. 대표적인 것으로는 오픈소스인 twemproxy가 있고 이것은 ascii 모드를 지원하는 데이터 샤딩을 할 수 있는 프락시이다.
쿼리 라우팅은 클라이언트의 요청을 받았을 때 처음에는 무작위 노드로 보내고 그 노드가 요청을 처리하기에 적합하지 않으면 대상노드로 리다이렉트 하는 형식의 라우팅이다. 레디스 클러스터는 앞서 언급한 방법 중 클라이언트 측 파티셔닝과, 쿼리라우팅을 결합한 형태이며 레디스 클러스터 프락시는 프록시 기반의 파티셔닝을 사용한다.
여기까지가 간단한 형태의 Redis Cluster에 대한 내용이고
다음에는 실제로 Docker compose를 사용해 redis cluster를 어떻게 구축할 수 있는지 알아보는 방법으로 글을 작성해 보겠다.
'DB' 카테고리의 다른 글
| [DB] JAVA 개발자라면 알아야 하는 SQL Best Practice (3) | 2024.10.23 |
|---|---|
| [DB] Redis Cluster Docker Compose로 구축하기 (4) | 2024.10.22 |
| [DataBase] 트랜잭션에 대해서 얼마나 알고있는가? (1) | 2024.10.11 |