1. 구성하게 된 이유
스타트업 프로젝트를 2주안에 서버 구축이 완료되어어야 한다는 소리에 다급하게 프로젝트를 시작하고
인프라 구축, API 개발까지 완료를 한 상황에서 물론 스스로 응답에 관련한 테스트는 진행했지만 내가 만든 서비스의 수용량, 즉 얼마나 많은 유저들이 접속해서 유지할수 있는지 파악이 되지 않았다. 그리고 만든 서비스는 MSA 구조로 나뉘어져 있는 구조였기 때문에 각 컴포넌트 끼리 통신을 주고 받는 경우가 많아 하나의 요청도 분산되어있는 서비스에서 추적이 가능해야 했다.
따라서 스트레스 테스트 과정중 Spring Boot의 Observability가 필요하다고 생각했고 그에 따라 구성해본 경험을 작성해보려고 한다.
2. 서비스 환경 버젼
(2025.01.04 기준 최신 latest 이미지만 사용했습니다)
- Spring Boot 3.3.2
- Java 21
- Docker
- 각 서비스 환경 구성
- Grafana
- API 스트레스 테스트, Spring Boot , CPU 메모리등 리소스 시각화
- InfluxDB
- API 스트레스 결과용 DB
- K6
- 스트레스 테스트 툴로 설정 : 리소스를 적게 잡아 먹어 같은 JVM을 사용하는 JMeter및 NGrinder보다 가벼운 장점
- Prometheus
- 각 서비스 컴포넌트 데이터 수집
- Digma
- OTLP 메트릭( opentelemetry 에서 제공하는 메트릭 ) 을 통해서 각 request 요청을 추적하고 파악하는 용도
- ZipKin
- 분산 추적 시각화 사용
2-1. Spring Boot 서비스 환경 구성
일단 각 서비스의 환경은 모두 docker로 구성했다. 하나의 프로젝트 안에 멀티모듈로 구성이 되어있으며 다음과 같은 DockerFile을 사용해 Build하게 된다.
#DockerFile
# 공통 베이스 이미지 설정
FROM amd64/amazoncorretto:21-alpine-jdk AS base
WORKDIR /app
# 공통 빌드 인스트럭션
FROM base AS builder
ARG SERVICE_NAME
COPY ${SERVICE_NAME}/build/libs/*.jar app.jar
# 최종 이미지 설정
FROM amd64/amazoncorretto:21-alpine-jdk
COPY --from=builder /app/app.jar app.jar
ENTRYPOINT ["java", "-Duser.timezone=Asia/Seoul", "-Dspring.profiles.active=docker", "-jar", "app.jar"]다음과 같이 구성을 해놓게 되면 프로젝트 Root 폴더, 최상위 폴더에 하나의 DockerFile을 사용하고 다음과 같은 Shell을 통해서 각 서비스에 맞게 빌드가 가능하다.
./gradlew :gateway-service:build -x test
docker build --build-arg SERVICE_NAME=gateway-service -t {저장할 서비스 이미지} .다음 예시는 gateway service를 build하는 내용인데 예를 들어 폴더의 tree구조는 다음과 같이 생겼다. (각 모듈의 gradle은 표시하지 않았다.)
├── build
├── chat-service
│ └── src
│ └── main
│ ├── java
│ └── resources
├── core
│ └── src
│ └── main
│ ├── java
├── discovery
│ └── src
│ └── main
│ ├── java
│ └── resources
├── gateway-service
│ └── src
│ └── main
│ ├── java
│ └── resources
├── gradle
│ └── wrapper
└── user-service
└── src
└── main
├── java
└── resources./gradlew :gateway-service:build -x test
docker build --build-arg SERVICE_NAME=gateway-service -t {저장할 서비스 이미지} ../gradlew :user-service:build -x test
docker build --build-arg SERVICE_NAME=user-service -t {저장할 이미지 이름} .예시오 같이 저런식으로 각 모듈의 이름을 통해서 각 서비스만 빌드하여 이미지로 생성할 수 있고, -x test옵션은 테스트 진행하지 않고 빠른 build를 위해서 설정해둔 것이니 production환경에서는 build 수행시 테스트도 진행할수 있게 변경하는 것을 추천한다.
이런식으로 각 모듈의 이미지들을 만들고 나서 Docker Compose파일로 각 서비스를 한번에 띄울수 있다.
services:
redis:
container_name: redis
image: redis:alpine
ports:
- "6379:6379"
networks:
- user-db
- grafana
restart: always
redis-for-gateway:
container_name: redis-for-gateway
image: redis:alpine
ports:
- "7000:6379"
networks:
- user-db
- grafana
restart: always
redis-exporter:
container_name: redis-exporter
image: oliver006/redis_exporter:latest
environment:
- REDIS_ADDR=redis://redis:6379
ports:
- "9121:9121"
depends_on:
- redis
networks:
- grafana
restart: always
zipkin:
container_name: zipkin
image: openzipkin/zipkin:latest
ports:
- "9411:9411"
networks:
- server
restart: always
chatDB:
container_name: chat-service-db
image: postgres
ports:
- "5555:5432"
environment:
- POSTGRES_USER={user이름}
- POSTGRES_DB={db이름}
- POSTGRES_PASSWORD={비밀번호}
volumes:
- chatdb:/var/lib/postgresql/data
networks:
- chat-db
restart: always
userDB:
container_name: user-service-db
image: postgres
ports:
- "5556:5432"
environment:
- POSTGRES_USER={user이름}
- POSTGRES_DB={db이름}
- POSTGRES_PASSWORD={비밀번호}
- POSTGRES_HOST_AUTH_METHOD=trust # 개발 환경에서만 사용
volumes:
- userdb:/var/lib/postgresql/data
- ./pg_hba.conf:/var/lib/postgresql/data/pg_hba.conf
networks:
- user-db
- user-db-network
restart: always
command:
- "postgres"
- "-c"
- "wal_level=replica"
- "-c"
- "max_wal_senders=10"
- "-c"
- "max_replication_slots=10"
- "-c"
- "hot_standby=on"
user-db-replica1:
image: postgres
environment:
- POSTGRES_USER={user이름}
- POSTGRES_DB={db이름}
- POSTGRES_PASSWORD={비밀번호}
ports:
- "5433:5432"
volumes:
- userdb-replica1:/var/lib/postgresql/data
networks:
- user-db-network
- user-db-replica1
entrypoint: |
bash -c '
rm -rf /var/lib/postgresql/data/*
chmod 0700 /var/lib/postgresql/data
echo "Initializing replica..."
pg_basebackup -h userDB -U postgres -p 5432 -D /var/lib/postgresql/data -Fp -Xs -P -R
docker-entrypoint.sh postgres
'
depends_on:
- userDB
restart: always
command:
- "postgres"
- "-c"
- "password_encryption=md5"
- "-c"
- "hot_standby=on"
- "-c"
- "wal_level=replica"
discovery:
image: {Discovery(유레카 서버)}:latest
container_name: discovery
ports:
- "8761:8761"
networks:
- server
restart: always
gateway-service:
image: {나의 gateway service}:latest
ports:
- "8081:8080" # multi gateway 포트 범위 지정
- "8080:8080" # single gateway 포트 범위 지정
environment:
- EUREKA_CLIENT_SERVICEURL_DEFAULTZONE=http://discovery:8761/eureka/
networks:
- user-db
- server
- grafana
depends_on:
- discovery
deploy:
replicas: 2
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failure
chat-service:
image: {채팅 서비스 이름}:latest
environment:
- EUREKA_CLIENT_SERVICEURL_DEFAULTZONE=http://discovery:8761/eureka/
networks:
- server
- grafana
- chat-db
depends_on:
- discovery
ports:
- "8084:8081"
- "8085:8081"
user-service:
image: {유저 서비스 이름}:latest
# container_name: user-service
environment:
- EUREKA_CLIENT_SERVICEURL_DEFAULTZONE=http://discovery:8761/eureka/
networks:
- server
- grafana
- user-db
- user-db-replica1
depends_on:
- discovery
ports:
- "8082-8083:8082" # 포트 범위 지정
deploy:
replicas: 2
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failure
networks:
server:
grafana:
external: true
user-db:
chat-db:
user-db-network:
user-db-replica1:
volumes:
mongodb:
chatdb:
userdb:
userdb-replica1:참고로 각 서비스의 Server Port는 모듈별로 상이하니 자신의 프로젝트에 적용하고 싶다면 포트번호를 잘 확인해서 변경하길 바란다. Docker Compose의 대해서 간단하게 설명하자면 여러 컨테이너들을 관리할 수 있는 오케스트레이션 툴중 하나이다. 대표적으로는 모두 잘아는 쿠버네티스가 유명한 오케스트레이션 툴이다. Docker Compose로 구성한 이유는 쿠버네티스의 복잡한 구성요소를 사용할 필요 없고, 간편하게 테스트 환경을 구성하고 작은 환경이라면 쿠버네티스의 오토스케일링으로 일어나는 오버헤드 또한 신경쓸 필요가 없기 때문에 Docker Compose로 구성을 했다.
Docker Compose를 사용할때의 주의점은 각 서비스간의 통신을 가장 주의깊게 살펴야 하는데 각각의 도커 컨테이너는 가상의 ip주소를 부여받게 되고, localhost로 테스트 하는 오류를 많이 범하는데 예를 들어 각 컨테이너끼리 통신을 하기 위해서 도커 어플리케이션을 Port 8080, 8081로 사용하고 각 서비스 통신을 8080 어플리케이션은 localhost:8081로 통신을 보내고, 8081어플리케이션은 localhost:8080으로 연결을 요청하는 등의 문제점들을 인식하지 못하고 사용하는 사람들이 많다.
그림으로 보면 다음과 같은데 컨테이너 내부가 아니라 외부에서 요청을 8080, 8081로 보내는 경우는 각 IP주소가 동일하고 요청된 포트를 통해서 포트포워딩이 되어있으면 요청이 가능하다.

그러나 실수를 하는 경우는 컨테이너 내부에서 요청을 보내는 경우인데 실패하는 경우 대부분의 사람들의 생각은 이런 생각이지 않을까 싶다.

하지만 사실 요청은 이런식으로 흘러가게 되면서 요청을 실패하기 때문에 작동원리를 잘 알고 있어야 한다. 즉 왼쪽은 아무것도 존재하지 않는 어플리케이션에 요청을 보낸것이고, 오른쪽은 스스로에게 요청을 보낸것이다.

이를 해결하기 위해서 Docker Compose파일에서 Network라는 키워드로 각 서비스가 통신할수있는 Network창구를 열어주고 같은 네트워크안에 있는 서비스들은 각 컨테이너의 서비스이름으로 통신을 할수 있다.
여기까지 간단한 Docker Compose 설명이고 그렇다면 스트레스 테스트 과정에서 어떤 것들을 확인해야 하는지 먼저 정해야한다.
3. 스트레스 테스트의 목표
스트레스 테스트를 왜 하는지가 중요한데 목표에 따라서 수집하는 Metric이 달라지기 때문이다. 스트레스 테스트를 통해 확인하고자 하는 주요 사항은 다음과 같다:
- 시스템이 과도한 부하에서 어떻게 반응하는가?
- 임계점(Threshold)은 어디에 있는가?
- 병목현상이 발생하는 지점은 어디인가?
목표를 명확히 설정하면 테스트 결과를 보다 효과적으로 분석할 수 있다.
3-1. 테스트 환경 구성
테스트 환경은 실제 운영 환경과 최대한 유사하게 구성해야 한다. 이때 다음 사항을 고려해야 한다:
- 서버 스펙: 실제 사용 중인 하드웨어와 동일한 사양을 사용하는지 확인.
- 네트워크 조건: 실제 네트워크 대역폭, 지연(latency) 등을 반영.
- 데이터베이스 설정: 운영 환경과 동일한 데이터 크기와 구성을 반영
나는 스트레스 테스트를 위해서 Dummy 데이터를 각 테이블마다 간단하게 10만개 정도 설정해주고 테스트를 진행했으며
서버 스펙을 맞추기 위해서는 Docker Engine의 설정을 통해서 Docker 컨테이너들이 활용하는 CPU, Memory 등을 지정할 수 있고, 이를 통해 CPU 8, Memory 4G로 맞춰 테스트를 진행했다.
3-2. 테스트 시나리오 작성
테스트 시나리오는 실제 사용 사례를 기반으로 작성해야 한다. 일반적으로 다음과 같은 상황을 고려한다:
- 동시 사용자 수가 급격히 증가하는 경우
- 데이터베이스에 대량의 읽기/쓰기 요청이 발생하는 경우
- 네트워크 트래픽이 급증하는 경우
3-3. 테스트 툴 선정
효율적인 스트레스 테스트를 위해 적합한 툴을 사용하는 것이 중요하다. 일반적으로 사용되는 툴로는 다음이 있다:
- Apache JMeter: 다양한 프로토콜을 지원하며, 확장성이 높다.
- Gatling: 고성능의 HTTP 기반 테스트 툴로, 코드 기반의 테스트 시나리오를 지원한다.
- Locust: Python으로 작성되며, 분산 테스트를 쉽게 수행할 수 있다.
- K6: JavaScript 기반으로 작성된 성능 테스트 도구로, 쉽게 스크립트를 작성하고 클라우드 환경에서도
테스트를 수행할 수 있다.
로컬로 테스트를 진행할 예정이기에 좀더 빠른 Go로 작성된 K6를 사용하기로 정했고, 충분한 부하를 줄수 있다는 점에 이끌려 K6로 결정했다.
3-4. 모니터링 설정
테스트 과정에서 실시간 모니터링이 매우 중요한데 다음과 같은 요소들이 필요했다.
- CPU 및 메모리 사용량: 시스템이 과부하 상태에서 리소스를 효율적으로 사용하고 있는지 확인.
- 네트워크 대역폭: 네트워크 병목 현상이 발생하는지 확인.
- 데이터베이스 상태: 쿼리 처리 시간, 연결 수 등을 모니터링.
- 애플리케이션 로그: 예외 및 오류 발생 여부를 확인.
3-5. 결과 분석
테스트 결과는 단순히 수집하는 것으로 끝나지 않고, 분석을 통해 개선 사항을 도출해야 한다. 주요 분석 포인트는 다음과 같다:
- 임계점을 넘어섰을 때 시스템은 어떻게 반응했는가?
- 성능 저하가 발생한 구체적인 원인은 무엇인가?
- 예상치 못한 오류나 장애가 발생했는가?
다음과 같은 요소들은 Spring Boot의 Actuator와 Prometheus의 의존성을 통해서 쉽게 구현이 가능했다.
gradle에 다음과 같이 의존성을 추가하고 application.yml이나 properties에 actuator를 열어주면 된다.
implementation 'org.springframework.boot:spring-boot-starter-actuator'
runtimeOnly 'io.micrometer:micrometer-registry-prometheus'management:
prometheus:
metrics:
export:
enabled: true
endpoints:
web:
exposure:
include: prometheus, health, info, metrics, opentelemetry다음과 같이 yml을 설정해주고 다시 Docker compose로 grafana, prometheus, influxdb를 실행한다.
grafana 는 연결된 데이터소스를 통해서 시각화를 할 수 있는데 여기서 진행할 내용은
CPU, Memory등 각 서비스의 JVM Metric은 Prometheus에서 서비스에 접근해 Metric을 수집하게 된다. 그리고 Influxdb는 k6에서 테스트 결과를 influxdb에 보내게 되고 grafana에서 이를 받아 시각화를 진행한다.
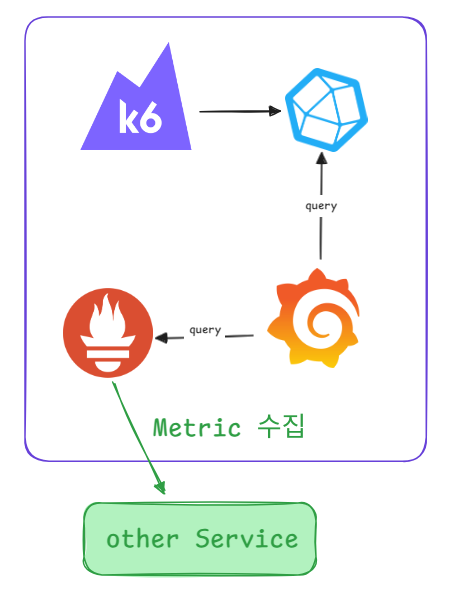
흐름을 시각화해보면 위와 같은 형태이며 진행하기 위해서는 우선 Docker Compose 파일을 생성한다.
networks:
k6:
grafana:
external: true
services:
influxdb:
image: influxdb:latest
networks:
- k6
ports:
- "8086:8086"
environment:
- INFLUXDB_DB=k6
grafana:
image: grafana/grafana
networks:
- grafana
- k6
ports:
- "3000:3000"
environment:
- GF_AUTH_ANONYMOUS_ORG_ROLE=Admin
- GF_AUTH_ANONYMOUS_ENABLED=true
- GF_AUTH_BASIC_ENABLED=false
volumes:
- grafana:/var/lib/grafana
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.retention.time=48h' # 데이터를 24시간 보관
- '--storage.tsdb.wal-compression' # WAL 압축 활성화
ports:
- "9090:9090"
networks:
- grafana
volumes:
grafana:
prometheus_data:그리고 prometheus에서 다음 설정파일에 따라서 어느 서비스의 메트릭을 수집할건지 지정해야한다.
#prometheus.yml
global:
scrape_timeout: 15s
scrape_configs:
- job_name: 'gateway-service'
metrics_path: '/actuator/prometheus'
scrape_interval: 10s # This can be adjusted based on our needs
static_configs:
- targets: ['{컨테이너 이름:포트번호}','{컨테이너이름}:{포트번호}']
- job_name: 'chat-service'
metrics_path: '/actuator/prometheus'
scrape_interval: 20s # This can be adjusted based on our needs
static_configs:
- targets: ['{컨테이너 이름:포트번호}','{컨테이너이름}:{포트번호}']
- job_name: 'user-service'
metrics_path: '/actuator/prometheus'
scrape_interval: 5s # This can be adjusted based on our needs
static_configs:
- targets:['{컨테이너 이름:포트번호}','{컨테이너이름}:{포트번호}']
- job_name: 'redis'
scrape_interval: 30s # This can be adjusted based on our needs
static_configs:
- targets: ['redis-exporter:9121']이렇게 지정하고 docker-compose에서 volume설정으로 파일을 마운트하도록 지정해놓게 되면 이 설정값으로 각 서비스를 읽으며 메트릭을 수집한다. 그리고 Docker compose 파일을 실행시키면 된다. 여기까지 진행했다면 http://localhost:3000 과 http://localhost:9090, 그리고 influxDB가 실행중일텐데 각 서비스르 제대로 추적하고 있는지 확인하기 위해서는 http://localhost:9090/service-discovery 에 들어가게 되면 각 서비스를 추적하고 있으면 확인되었다는 표시가 뜬다.

그럼 다음으로 K6를 실행시킬수 있는데 실행되고 나서 확인해볼 지표들은 다음에서 확인해볼수 있고 어떻게 시나리오를 작성하고 테스트 했는지, 지표들을 확인하고 어떻게 코드를 개선시켰는지 다음 2편으로 찾아보도록 하겠다.
Spring Boot 프로파일링 및 Stress Test [Spring]
현재 진행하고 있는 프로젝트의 대한 최적화를 진행하기 위해 다음과 같은 기술 스택을 사용했고 어떻게 진행했는지, 어떤 과정으로 나아갔는지 작성해보도록 하겠다.Spring Boot 3.3.2Java 21Docker각
kiru-dev-study.tistory.com
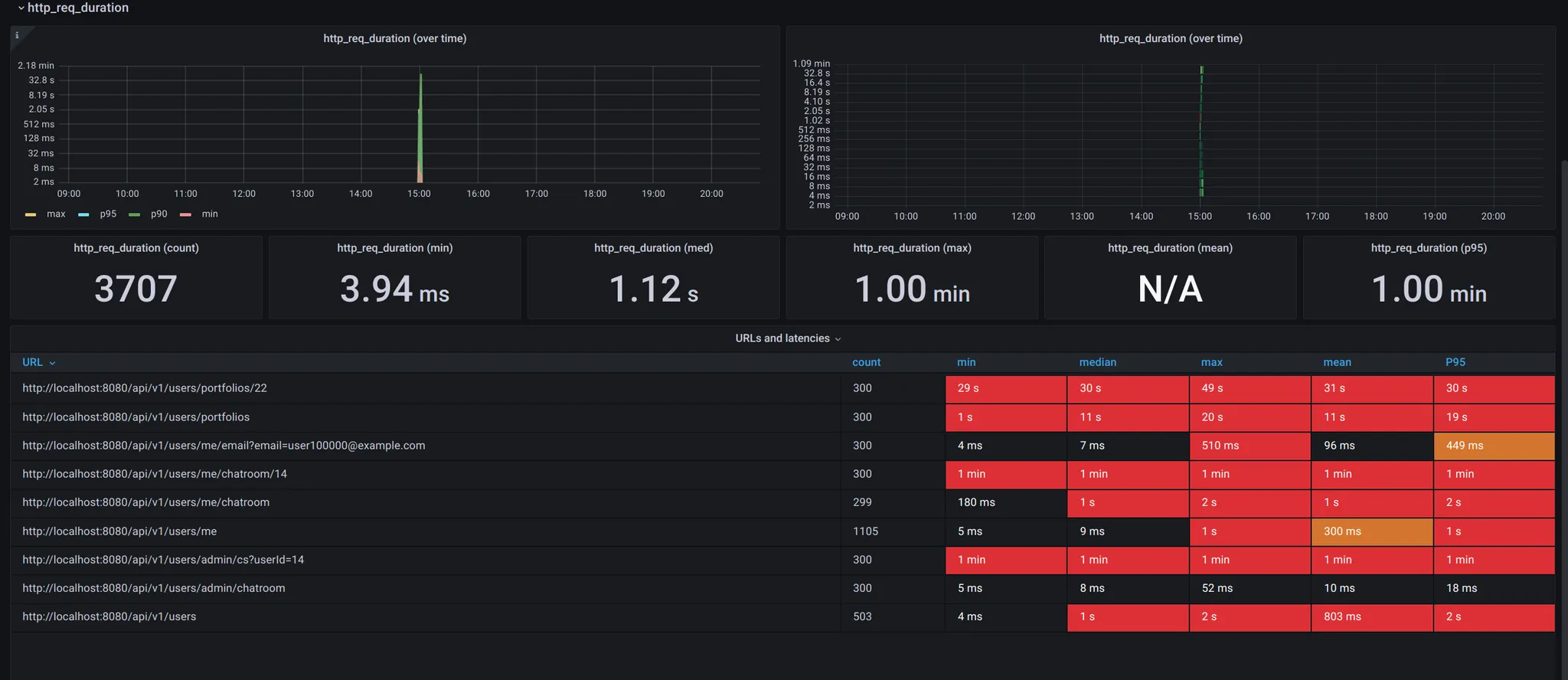
결과만 놓고 보자면 다음 테스트에서 시간을 보면 전체적으로 성능이 좋지않은 모습을 보여주는데

Observavility를 구성하고 Stress테스트를 통해서 서버를 최적화 한 결과 거의 100배의 요청수준에도 더 적은 request duration을 보여주며, 성능을 매우 높게 끌어올릴 수 있었다.

'Spring' 카테고리의 다른 글
| Spring Boot 서비스 환경 스트레스 테스트 3 [Spring/Java] (0) | 2025.01.17 |
|---|---|
| Spring Boot 서비스 환경 스트레스 테스트 2 [Spring/Java] (0) | 2025.01.08 |
| Spring Boot 프로파일링 및 Stress Test [Spring] (0) | 2024.12.21 |
| 멀티모듈 프로젝트 Docker 빌드 전략: Path 기반 접근법[Docker&Github Action] (1) | 2024.12.14 |
| 가상 스레드 vs 반응형 프로그래밍 [Spring/Java] (2) | 2024.11.22 |