https://kiru-dev-study.tistory.com/27
Spring Boot 서비스 환경 스트레스 테스트 [Spring/Java]
1. 구성하게 된 이유스타트업 프로젝트를 2주안에 서버 구축이 완료되어어야 한다는 소리에 다급하게 프로젝트를 시작하고 인프라 구축, API 개발까지 완료를 한 상황에서 물론 스스로 응답에
kiru-dev-study.tistory.com
1편에 이어서 어떻게 개선했는지 확인해 보도록 하겠다.
스트레스 테스트에서 가장 중요한 점은 어디서 병목이 생기는지, 왜 병목이 생기는지에 대한 부분이다.
1. 병목 지점 - DB
실제로 가장 큰 병목 지점은 DB/IO의 대한 부분이다. 왜 그런가 하면 DB의 구조를 생각하면 좋은데 DB는 디스크에 데이터가 저장되게 된다. 즉 DB를 조회한다는 것은 디스크에 접근하는 부분이기 때문에 가장 느려질 수밖에 없는 구조다.
또한 Spring Boot에서는 DB에 대한 접근 조회를 고정된 Connection Pool을 사용하게 되어 DB에 연결할때 효율적인 구조를 추구하지만 그래도 여전히 DB에 접근해서 데이터를 가져오는 부분은 큰 병목현상으로 이어지게 된다.
따라서 비즈니스 로직상에 ACID를 지켜 꼭 최신의 데이터를 조회하는 것을 필요한 부분을 제외하면 캐시처리하는 것이 좋다.
즉 방법은 2가지로 나뉠수 있다.
- 쿼리최적화 : 꼭 DB에 접근해야 하는 로직에 사용한다.
- 캐시 : 꼭 최신의 데이터를 보여줄 필요가 없거나, 고정된 값을 내려주는 경우 사용한다.
하지만 쿼리최적화는 DB에 접근하는 것 외에도 계산능력이나 속도를 빠르게 해 주기 때문에 캐시로 처리하더라도 해주는 편이 좋다.
1-1 쿼리 관련 최적화
https://kiru-dev-study.tistory.com/23
[DB] JAVA 개발자라면 알아야 하는 SQL Best Practice
https://www.baeldung.com/ 여기서 다음 글을 찾아서 좋은 내용이라고 생각해 한번 글을 작성해보려고 한다.https://foojay.io/today/sql-best-practices-every-java-engineer-must-know/ 여기서는 Java Engineer라면 모두 알아야
kiru-dev-study.tistory.com
쿼리 최적화에 대한 부분은 가볍게 이 글에서 확인할수 있다. 하지만 여기서도 논쟁이 생기는 부분은 JOIN을 쓰는 것보다 서브 쿼리를 사용할 때가 더 빠를 때도 있습니다!라는 논쟁으로 원 블로거의 댓글을 보면 논쟁을 벌이는 것을 볼 수 있다.
가장 좋은 쿼리 최적화 방법은 비즈니스 로직에 맞게 인덱스를 설정하거나 ( 읽기가 많은 경우 ), EXPLAIN 키워드로 쿼리실행계획을 확인하면서 직접 쿼리를 테스트 해볼 수 있다. EXPLAIN에 대한 내용은 다음에 좀 더 구체적으로 블로그를 작성해 보도록 하겠다.
하지만 가장 좋은 방법은 쿼리를 합쳐 DB에 대한 접근을 최소한으로 하는 것이 중요하다고 생각한다.
예를 들자면 다음 쿼리처럼 가져올수 있는 데이터를 전부 합치는 방식이다.
@Query("SELECT cr, " +
"COUNT(DISTINCT m.id) AS unreadMessageCount, " +
"lm.content AS latestMessageContent, " +
"STRING_AGG(CAST(uj.userId AS string), ',') AS participants " +
"FROM ChatRoomJpaEntity cr " +
"JOIN UserJoinChatRoom uj ON cr.id = uj.chatRoomId " +
"LEFT JOIN MessageJpaEntity m ON cr.id = m.chatRoomId AND m.readStatus = false AND m.senderId <> :userId " +
"LEFT JOIN MessageJpaEntity lm ON cr.id = lm.chatRoomId AND lm.createdAt = (" +
"SELECT MAX(lm2.createdAt) FROM MessageJpaEntity lm2 WHERE lm2.chatRoomId = cr.id) " +
"WHERE uj.chatRoomId IN (SELECT uj2.chatRoomId FROM UserJoinChatRoom uj2 WHERE uj2.userId = :userId) " +
"GROUP BY cr.id, lm.content")
Slice<Object[]> findChatRoomsByUserIdWithUnreadMessageCountAndLatestMessageAndParticipants(Long userId,
Pageable pageable);기존의 코드는 저 쿼리들이 다 분리되어있어, 각각 DB에 접근해서 채팅방 Id를 가져오는 쿼리, user를 가져오는 쿼리, message를 가져오는 쿼리가 전부 나뉘어 있어 DB에 한번 조회하는 것이 아닌 각각 따로 조회하였다. CompletableFuture를 사용하고 VirtualThread를 사용해서 별 문제가 없다고 판단했었지만 스트레스 테스트에 나타난 결과로는 곧 DB connection pool 부족 문제가 뜨는 경우가 많았다.
1-2 쿼리 : QueryHints
필자가 주로 사용하는 QueryHints 내용이다. 이와 별개로 더 많은 QueryHint옵션이 있으니 찾아보면 좋다.
@QueryHints(value = {
@QueryHint(name = "org.hibernate.readOnly", value = "true"),
@QueryHint(name = "org.hibernate.fetchSize", value = "150"),
@QueryHint(name = "jakarta.persistence.query.timeout", value = "5000")
})위의 내용은 hibernate에게 쿼리가 날아가기전 Query에 대한 Hint를 준다는 것이다. transaction을 readonly로 설정하고 , 한 번에 가져오는 fetchSize를 제한해서 큰 데이터를 한 번에 가져올 때도 최적화를 할 수 있다. 또한 query에 대한 timeout을 임의로 지정할 수도 있어 예상되는 동작을 수행시킬 수 있다는 장점이 있다.
가장 중요한 부분은 readOnly인데 @Transaction(readOnly=true)와 비슷하게 동작하지만 목적성에 있어서 다르다.
@QueryHints는 특정 쿼리수준에서 JPA 쿼리에 대해 Hibernate 구현체의 특정 설정을 제공할 때 사용하고 QueryHint로 readOnly를 적용하면 영속성 콘텍스트에서 dirtyChecking을 발생시키지 않아 성능이 조금 더 올라간다.
@Transactional(readOnly=true)는 Spring 트랜잭션 관리 영역에서 선언되며, 트랜잭션 범위 전체에 사용된다.
이렇게 되면 Hibernate의 flush를 생략하기 때문에 불필요 SQL이 데이터베이스로 전송되지 않도록 함으로서 최적화가 된다.
표로 보면 다음과 같은 내용으로 표현된다.
| 적용 범위 | 특정 쿼리 수준에서만 적용 | 트랜잭션 전체(메서드/클래스) |
| 목적 | 쿼리 실행의 최적화 및 동작 변경 | 트랜잭션의 읽기 전용 보장 및 최적화 |
| 데이터베이스 설정 | Hibernate와 데이터베이스 간의 통신 관련 설정 제공 | 데이터 쓰기 작업 방지 |
| 영향 | 쿼리 실행 시 fetch size, timeout 등 세부 동작 설정 가능 | Hibernate의 flush 생략, 데이터베이스 쓰기 작업 차단 |
| 사용 상황 | 특정 쿼리 최적화 필요 시 사용 | 읽기 작업만 수행하는 트랜잭션을 처리할 때 사용 |
1-3 데이터 전송량 줄이기
또한 가져오는 데이터가 많다면 데이터에 대한 네트워크 통신 비용까지 올라가며 네트워크가 속도가 떨어질수 있다.
따라서 Pageable을 사용해 가져오는 데이터를 줄이는 것도 최적화 방법중에 하나이다.
스트레스 테스트를 위해서 dummy data를 각 테이블마다 10만개씩 만들어놓고 테스트를 했기 때문에 전체조회시라면 10만 개의 레코드를 전부 가져올 수 있어, pageable을 사용하여 데이터를 일정 부분만 가져올 수 있도록 하였다.
2. 병목 지점 - DB
그래도 여전히 DB가 병목지점일 수 있는데, 어플리케이션 관점에서 DB에 접근한다고 해보자.
SpringBoot에서 DB Connection Pool의 개수가 10개라고 가정한다면, 동시접속자 (Vuser)가 10명이고 DB에 접근하고 조회하는데 1초가 걸린다고 했을 때, 나머지 User는 연결이 되어있어도 DB의 접근하기 위해서 기다려야 하면서 점차 병목이 생기기 시작한다. 즉 DB Connection Pool을 적정 개수로 설정하거나, Connection을 재빨리 돌려줘야 한다는 결론이 나온다.
즉 이를 위해서 위의 1의 DB에 접근하는로직들을 최적화해준 것이다. 최적화를 마쳤더라면 DB Connection Pool도 적절하게 설정해줘야 하는데 이는 찾아보면 CPU 코어수*2로 설정하는 게 좋다고 한다. 왜냐면 CPU가 최대한 콘텍스트 스위칭 비용을 낮출 수 있고 빠른 반환을 제공한다. 디스크나 네트워크를 통한 IO는 스레드를 블락시키기 때문에 최대한 활용할 수 있는 방식으로 CPU
또한 활용해야 한다.
2-1. 병목 지점 - @Transactional
개발자들이 흔히 하는 실수는 불필요하게 트랜잭션을 남발하면서 DB의 커넥션을 가져온다는 것인데 위에서 말했듯이 디스크나 네트워크를 통한 IO는 스레드를 블락시킨다. 그리고 Spring Boot를 활용하면서 @Transactional 키워드로 편리하게 커넥션을 가져올 수 있지만 이는 주의하면서 사용해야 하는데 빠른 DB 커넥션을 반환하기 위해서 주의해야 할 사항이다.
그림으로 보면 다음과 같다.

다음 그림처럼 내부 로직들이 하나의 트랜잭션으로 묶여있다면 무슨일이 일어날까? 실제로 DB의 접근해서 필요한 부분은 1,2,3의 대한 부분이다. 그런데 사이에 네트워크 IO를 호출하게 되면서 각기 동작이 비동기로 수행되어 일어났다고 하더라도 해도 하나의 트랜잭션으로 묶여있어 네트워크가 호출되는 동안 계속해서 DB connection을 잡고 있게 된다.
따라서 이렇게 불필요한 트랜잭션 과사용은 지양해야 하며 이를 통해서도 DB connection을 빨리 반환할수 있다.
주로 이런 경우 MSA에서도 많이 일어나는 상황인데 MSA를 적절하지 설계하지 못했거나, 서비스로직 상에서 문제가 생길 수 있기 때문에 각기 담당하는 서비스에 담당하는 DB에만 변경사항이 일어날 수 있도록 MSA를 설계하는 것이 바람직하다.
위 그림에서 단순히 Select하는 로직만 담당한다면 @Transactional 어노테이션을 붙이지 않고 사용하는 것도 좋다.
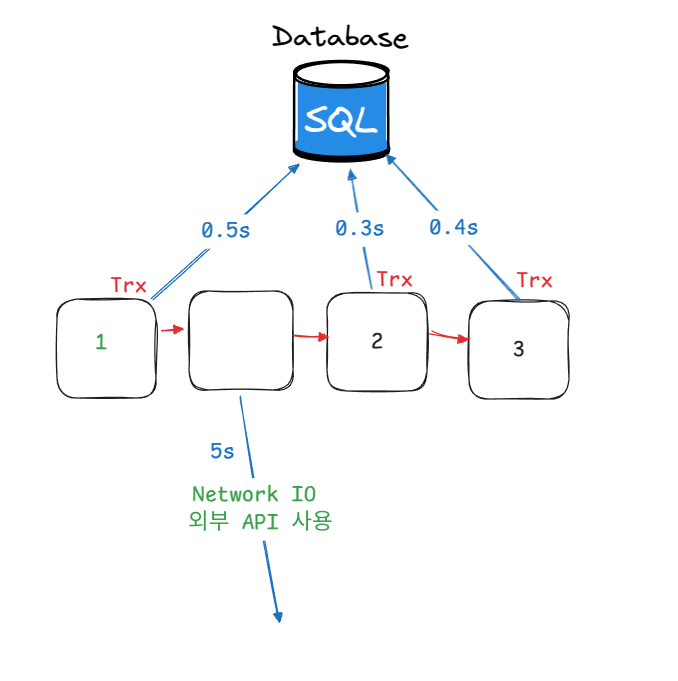
그렇게 된다면 다음 그림처럼 각각의 트랜잭션을 사용하면서 DB 커넥션을 빠르게 반환할수 있고 트랜잭션이 필요한 다른 요청이 빠르게 사용할 수 있다. 혹은 LazyConnectionDataSourceProxy를 등록할 수도 있는데 다음은 실제로 DB에 대한 요청이 날아갈 때만 DB 커넥션을 사용할 수 있게 하면서 불필요한 트랜잭션을 막아주니 다음 Bean을 등록해 주는 것도 좋은 중에 하나이다.
@Configuration(proxyBeanMethods = false)
@RequiredArgsConstructor
@Profile({"dev","test"})
public class LazyDataSourceConfig {
@Value("${db.connections}")
private int connections;
@Bean
public DataSource lazyDataSource(DataSourceProperties properties) {
HikariDataSource dataSource = properties.initializeDataSourceBuilder()
.type(HikariDataSource.class)
.driverClassName(properties.determineDriverClassName())
.password(properties.determinePassword())
.url(properties.determineUrl())
.username(properties.determineUsername())
.build();
dataSource.setMaximumPoolSize(connections); // Connection pool size 설정
dataSource.setPoolName("HikariPool-User");
return new LazyConnectionDataSourceProxy(dataSource);
}
}3. DashBoard 확인
이제 다시 스트레스 테스트 진행으로 돌아와서, 기본적인 Grafana와 Prometheus의 사용법은 1편에서 Docker Compose로 띄울수 있게 했으니 다음 DashBoard를 사용해서 내 Spring Boot Application을 살펴보자.
https://grafana.com/grafana/dashboards/19004-spring-boot-statistics/
Spring Boot 3.x Statistics | Grafana Labs
Import the dashboard template Copy ID to clipboard or Download JSON
grafana.com
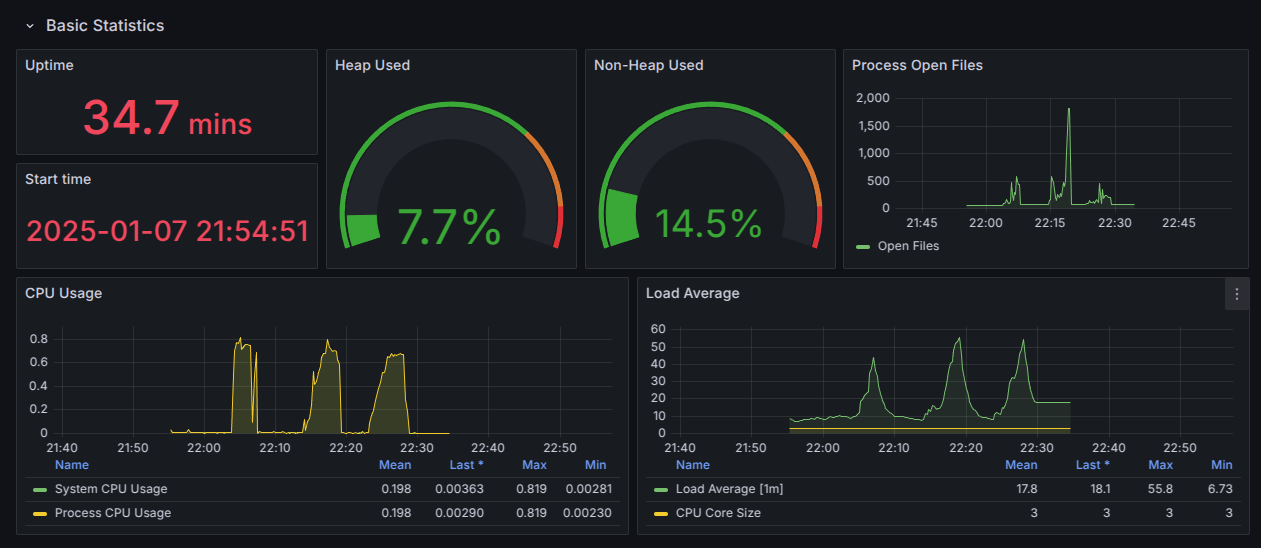
각각에서 볼수 있는 점은 다음과 같다
- Application 실행시간
- Heap 사용량
- JVM 내에서 객체가 생성되고 저장되는 메모리
- Process Open Files
- JVM의 Heap 영역 이외의 메모리 영역에서 현재 사용 중인 메모리 양을 표시
→ 주로 JVM 자체의 동작에 필요한 메타데이터, 스레드 관련 정보를 저장한다.
- JVM의 Heap 영역 이외의 메모리 영역에서 현재 사용 중인 메모리 양을 표시
- CPU 사용량
- Load Average
- 시스템에서 CPU를 얼마나 사용하는지 확인
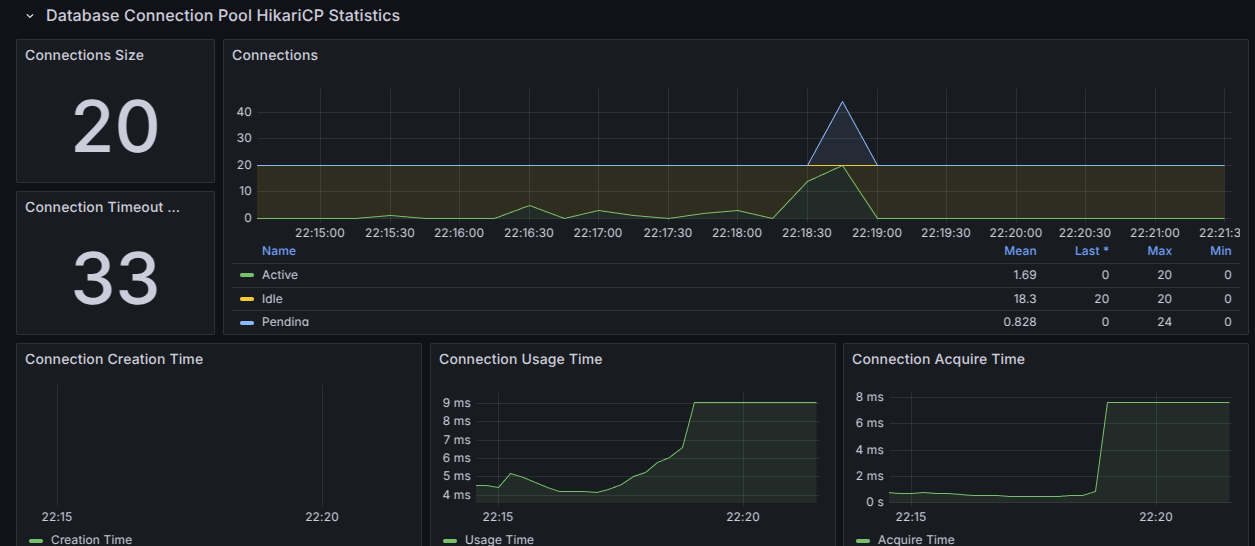
- 현재 DB connection 개수
- pending Thread : DB connection을 기다리는 스레드
- Active Thread : DB에서 작동 중인 Thread 개수
- Idle Thread : 설정한 DB connection Idle 개수
일단 스트레스 테스트에서 확인해볼수 있는 지표들은 이외에도 GC에 관련된 지표들이 더 있지만 기본 Spring Boot에서 제공하는 기능으로 부족하다면 GC 튜닝을 통하는 것도 좋다.
위 그림에서는 DB connection에서 Pending thread가 많아져 DB에 대한 connection Timeout이 발생한 부분에 대한 그림이다.
위처럼 그림이 나온다면 DB connection Pool을 늘리거나, db에 접근하는 로직을 캐시처리하는 등의 방식을 진행해야 한다.
먼저 JVM 시스템 관점에서 CPU, 메모리, DB connection등을 확인해서 적절한 최적화를 진행할 수 있는데 방대한 양의 코드 속에서 어느 부분에 병목이 생기는지 확인하는 것은 어렵다. 따라서 전체적인 API에 대한 스트레스 테스트 진행, 그리고 개별 API에 대한 스트레스 테스트 진행을 진행해 보면서 어느 부분에서 병목이 생기는지 확인하는 것도 스트레스 테스트의 한 방법이다.
다음 내용으로 어플리케이션 레벨에서 코드의 어느 부분에서 병목이 생기고 어떻게 확인하는지 블로그로 작성해 보도록 하겠다.
최종적으로 Stress Test시 다음의 그림처럼 나오게 된다.


'Server' 카테고리의 다른 글
| 객체지향적으로 코드 리팩토링 하기 [Spring/Java] (2) | 2025.01.25 |
|---|---|
| Spring Boot 서비스 환경 스트레스 테스트 3 [Spring/Java] (0) | 2025.01.17 |
| Spring Boot 서비스 환경 스트레스 테스트 [Spring/Java] (1) | 2025.01.04 |
| Spring Boot 프로파일링 및 Stress Test [Spring] (0) | 2024.12.21 |
| 멀티모듈 프로젝트 Docker 빌드 전략: Path 기반 접근법[Docker&Github Action] (1) | 2024.12.14 |